Disaster recovery setup
Overview
Prior to configuring Vault, it is essential to plan for potential infrastructure failures. HashiCorp advises that Vault Enterprise customers implement, at a minimum, a disaster recovery (DR) solution for their production clusters.
Note
HCP Vault cluster DR posture is managed by the HCP Platform. For more information please review the High Availability and Disaster Recovery documentation.
Prerequisites
- You have reviewed and implemented the HashiCorp Vault Solution Design Guide HVD.
- You have deployed two separate Vault clusters, one acting as the DR primary, and the other acting as at the DR secondary.
- The DR Vault clusters are initialized and unsealed.
- You have a valid root tokens for your clusters.
Types of cluster replication in Vault Enterprise
Vault can be extended across data centers or cloud regions using the replication feature of Vault Enterprise. Vault replication operates on a leader/follower model, wherein a leader cluster (known as a primary) is linked to a series of follower secondary clusters to which the primary cluster replicates data.
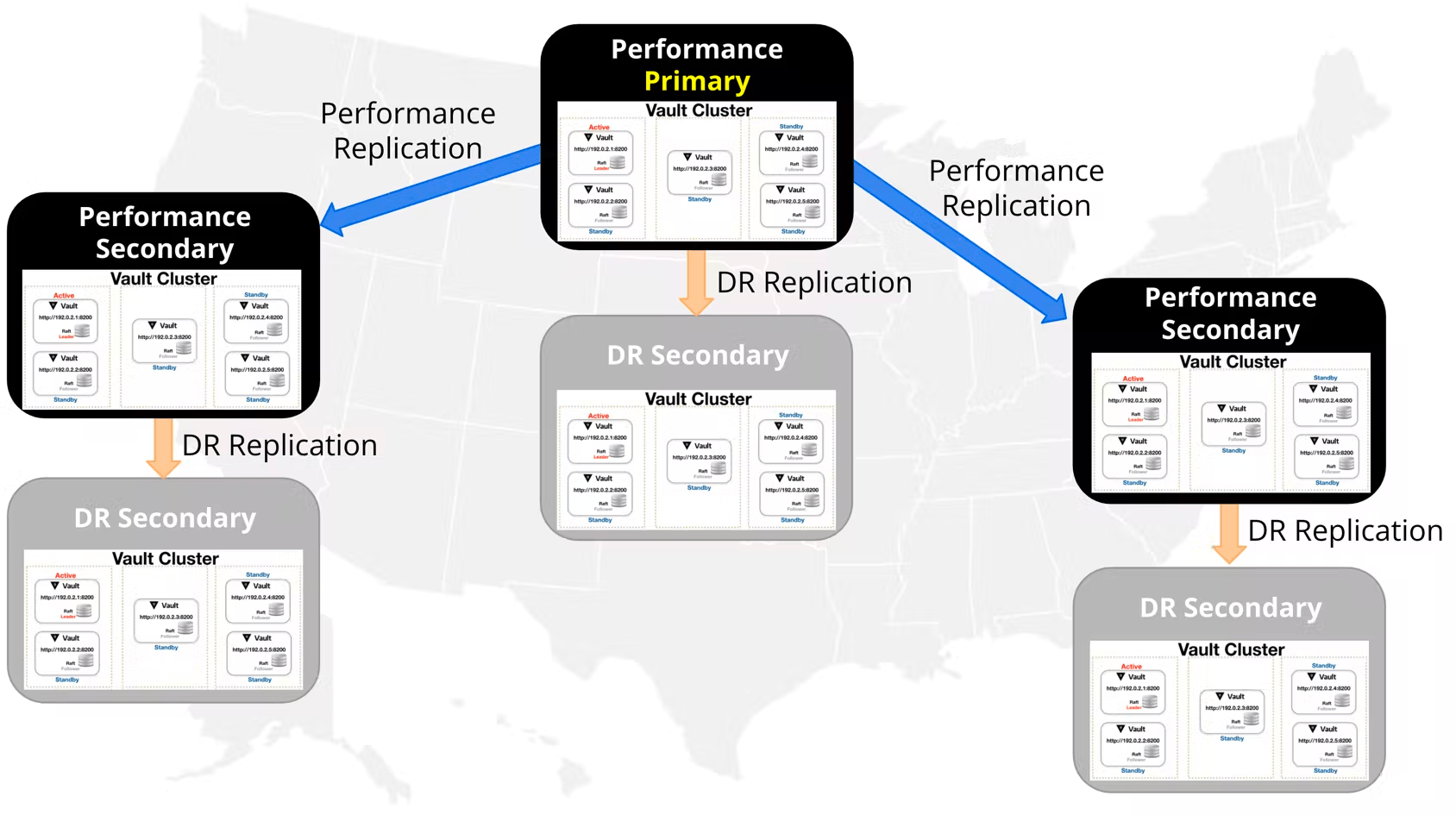
The data replicated between the primary and secondary cluster is determined by the type of replication: disaster recovery (DR) or performance replication (PR).
A DR secondary cluster is a complete mirror of its primary cluster. DR Replication is designed to be a mechanism to protect against catastrophic failure of entire clusters. DR secondaries do not service read or write requests until they are promoted and become a new primary. A DR secondary cluster acts as a warm standby cluster.
A PR secondary cluster replicates everything from the primary except for tokens, leases (dynamic secrets), and any local(opens in new tab) secrets engines, and is covered in this document(opens in new tab).
Setting up DR replication
At this point, you should have two Vault Enterprise clusters: one that will act as the DR primary cluster, and another that will become the DR secondary cluster. We strongly advise carefully reading and implementing the details provided in the official documentation on disaster recovery replication set up(opens in new tab).
Configure DR operation token
A DR operation token is required to promote a DR secondary cluster as the new primary. This token should be created in advance and stored safely outside of Vault in case of a failure condition that would warrant the promotion of the DR secondary cluster.
Because the DR operation token has the ability to fundamentally modify your Vault clusters' topology and operation, it should be securely stored and time limited with an expiration date. While the public document regarding DR operation token strategy suggests that you can create a batch token as an alternative to a DR operation token, we recommend that you use the former, which can be generated from the DR primary cluster without your recovery keys (or unseal key if you are not using auto-unseal). The batch DR operation token has a fixed TTL and the Vault server will automatically delete it after it expires.
Note
You must have permission to call the auth/token/create endpoint in the root namespace for this CLI command. In the Configure Admin Policy section, you will configure a policy with super administrators access to call this API in the root namespace.
The recommendation to create a batch DR operation token means the operations team have such but that this is valid for eight hours. Use the token in such a way that when a Vault operator comes on a shift, the operator generates a batch DR operation token with a TTL equal to the duration of the shift.
DR cluster promotion
Deciding when to initiate a DR process on Vault can be a complex decision. Due to the difficulty in accurately evaluating why a failover should or should not happen, Vault Enterprise deliberately does not support an automatic failover/promotion of a DR secondary cluster. However, It is possible to automate accurate detection with your own development/tooling, and triggering/orchestrating failover by leveraging Vault's API, specifically the Replication(opens in new tab) and DR(opens in new tab) APIs.
In this section, we will outline the identification and manual activities to failover to a DR cluster.
When to initiate a DR process
We might think we will be able to identify a situation that should drive a DR process at the time it occurs, but usually this is not the case. Complex network topographies, ephemeral cloud resources, and unreliable metrics/health indicators can all falsely alert to an outage or quietly suppress a true outage.
Initiating a DR process for Vault is usually part of an organization-wide issue such as connectivity or a datacenter outage, versus a siloed problem with the Vault cluster. Vault itself is designed and should be deployed in a highly-available(opens in new tab) model that is tolerable to common issues such as a server losing a disk drive.
When Vault is deployed inline with the architecture outlined in the HashiCorp Vault Enterprise Solution Design Guide, two availability zones can fail with Vault still maintaining quorum, operation, and performance.
In the diagram below, the Vault leader node (voter) is in Availability Zone B. If it fails, the follower node (non-voter) in Availability Zone B will be elected as the new leader node (voter) and continue operation. The specifics of how active node step-down, leadership lost, and Raft election are outside the scope of this document.
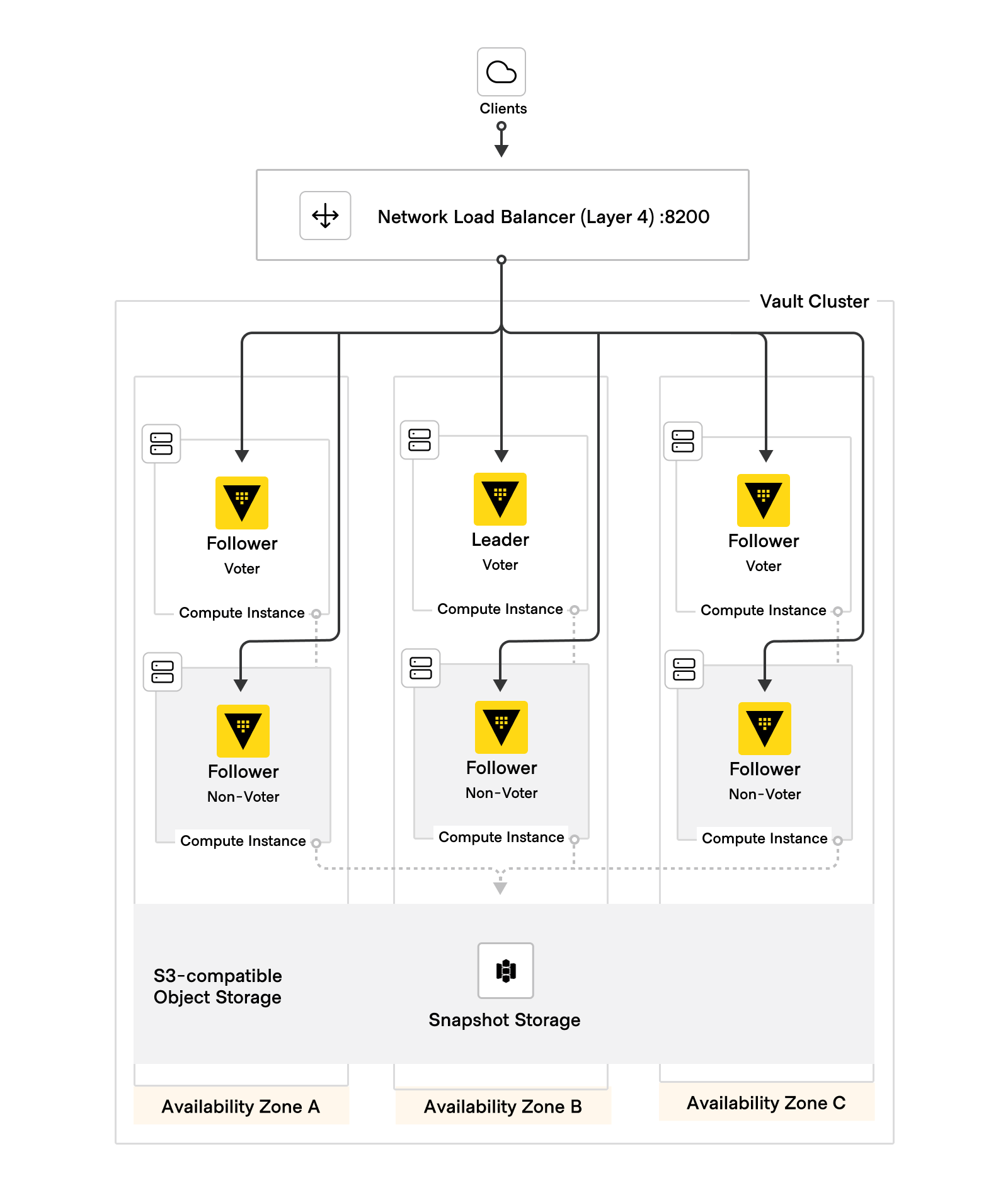
Vault operators should have a runbook to handle every combination of losing a node or nodes in the above architecture. For example, if a node in Zone C fails overnight it might be acceptable to wait until the next day to replace it in the cluster. However, a loss of connectivity entirely to Zone B and C might trigger action to replace those lost nodes immediately in Zone A, as once 4 nodes are lost the cluster has no more redundancy for maintaining quorum.
In the context of DR, two scenarios should initiate an immediate process to failover to a DR cluster:
- A rapid loss of all voter nodes such as a failure of all three availability zones.
- Failure of more than 4 nodes across all three availability zones - a minimum of 2 voter nodes are required to maintain quorum.
Identification of issues
Reactive awareness
Initial awareness and triage of a condition that could trigger a DR move is the first step to understanding what is going on, where the breakdown is, and which team/platform needs to be involved to resolve it. A few examples of methods for this include the following.
- Application alerting (ie, application cannot connect to Vault)
- Container/Server logs
- APM/tracing tools (Zipkin, Jaeger, Dynatrace, Datadog APM, etc)
- Vault logs
- Vault telemetry
- End-user complaints
Proactive action
Outside of reactive awareness of an issue, there are situations that your business continuity plan might prescribe a move to a DR environment ahead of the actual event. Examples of this include expecting and planning for a pending disaster, such as many financial organizations failing over to non-coastal datacenters when hurricane Sandy approached the New York area in 2012.
Confirmation of issue
Upon notification that something might be wrong, your organization should take one of two paths of action depending on the criticality and urgency of the possible outage.
- Immediately begin failover procedures.
- Execute a pre-authored and pre-tested triage runbook to verify which components are functioning and which have failed. Then, staff will decide to initiate a failover, fix the system within the primary environment, or possibly accept the period of outage.
The triage runbook is a specific set of verifications and conditions to assure staff makes the best decision to perform a DR move or not. For Vault, these can include:
- Are all services that use Vault experiencing problems, or one/subset?
- Is Vault itself (logs, telemetry) indicating a problem?
- Is there current maintenance that is possibly causing false alarms?
- Is Vault the actual issue, or could it be downstream (ie, the auth Vault uses to a cloud provider has been revoked)?
- Is the Vault cluster and each node responding if accessed directly vs through the load balancer?
- Is the issue something that would have been replicated to the DR cluster already (ie, accidental mass-revocation of tokens, or configuration change)
- WIll DR resolve this issue? Or will we need to restore from backup?
Confirmation of issue is important to protect the uptime of the service. Having an automated means to failover may reduce outage time, but we do not recommend fully automated failover.
How to initiate a DR process
Once an outage has been confirmed, operations staff should have a standard set of procedures to address the outage in order to minimize downtime, ensure data consistency, and notify others about outages, rollbacks, or new infrastructure to employ in a DR event. Given the multi-cluster architecture below as documented in the HVD for Vault Solution Design, in the event of a failure of DR primary cluster in Region 1, the recommended steps to promote the DR secondary cluster in Region 2 as the new primary are:
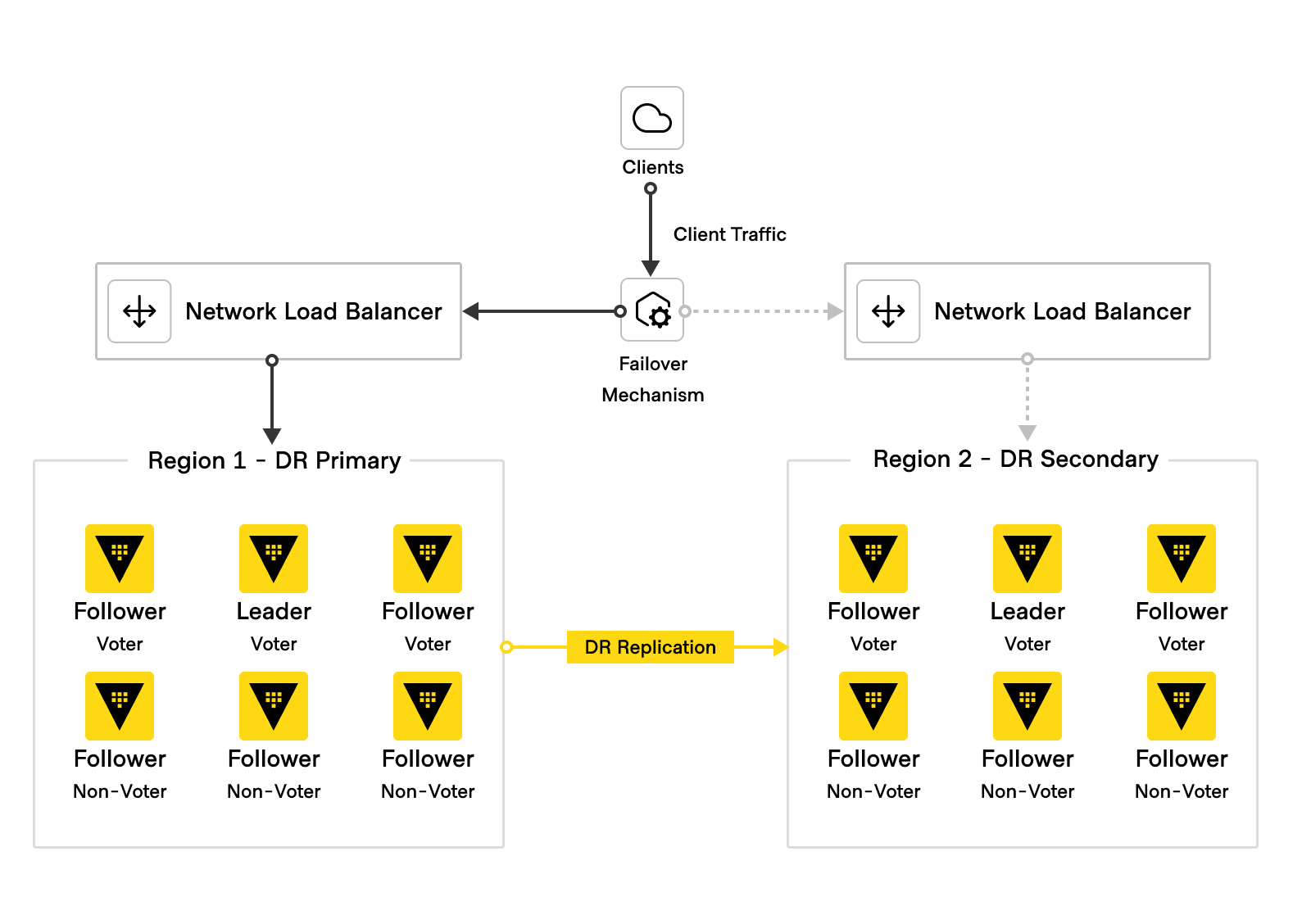
The prerequisite is to have generated a Batch DR operation token(opens in new tab) as per the advice above.
Follow the steps below.
Disable load balancing/routing while failover is in progress:
Disable the network load balancer to Region 1 Vault nodes.
Disable global load balancer (e.g. F5 GSLB, Amazon Route53 Failover Record, HashiCorp Consul). Recall the requirement of a failover mechanism in the HVD for Vault Solution Design.
Promote Region 2 DR secondary cluster to become the new primary cluster.
Configure your working environment:
Set
VAULT_ADDRto the address of the DR secondary cluster load balancer.Verify connectivity and cluster information with
vault status.- Promote DR secondary cluster from secondary to primary(opens in new tab)
Verify Region 2 Vault cluster is acting as a primary, that it has no secondaries, mode is primary, and its state is running:
vault read sys/replication/dr/status --format=json { "request_id": "ba05db44-2d64-174c-6857-9d7507fcf625", ... "data": { "cluster_id": "78a9148d-0c9b-49e9-f025-a997811e756e", "known_secondaries": [], "last_dr_wal": 3476845, "last_reindex_epoch": "0", "last_wal": 3476845, "merkle_root": "83ca160168dd2609ae8be43595915ebcd4d3415a", "mode": "primary", "primary_cluster_addr": "", "secondaries": [], "state": "running" }Enable load balancing to the new cluster:
Configure global load balancer to target Region 2 Vault cluster load balancer.
Verify connectivity to Region 2 Vault cluster via browser.
Notify Vault consumers and stakeholders Vault is back online.
As soon as the old primary is accessible, demote it to prevent split brain scenario, since Region 2 is now Primary.
Set
VAULT_ADDRto the address of a Region 1 DR primary node.- Demote Region 1 DR primary to secondary(opens in new tab).
How to failback
After the original primary has been restored to operation, it may be necessary or desirable to revert the configuration to the preferred topology. The recommended steps to failback are in this section(opens in new tab) of the public documentation on the subject, and additional considerations are below. In the example above, Region 2 is the current Primary, and Region 1 was the old primary and will be promoted again.
The prerequisite is to have generated a Batch DR operation token(opens in new tab) as per the advice above.
Considerations
- If you have not yet demoted the Region 1 old primary (see Step 5 above), you must do that before bringing it online and resuming replication. Demote Region 1 DR primary cluster to become secondary.
- Monitor Vault replication(opens in new tab) to ensure that the WAL (write ahead logs) are in sync: 1. Ensure that state of the secondary is `stream-wals`. 1. `merkle_root` on the primary and secondary should match. 1. The `last_dr_wal` on the primary should match the `last_remote_wal` on the secondary.
- Notify Vault consumers and stakeholders of planned outage for failback to Region 1.
- Disable load balancing/routing while failback is in progress:
- Disable load balancer to Region 2 DR primary.
- Disable global load balancer.
- Demote Region 2 DR primary to a secondary:
- Set
VAULT_ADDRto a Region 2 DR secondary node. - Demote the Region 2 DR primary to secondary.
- Set
- Promote Region 1 DR secondary as the new primary(opens in new tab) and verify Region 1 Vault cluster is acting as a primary, that it has no secondaries, mode is primary, and its state is running.
- Establish replication between Region 2 DR secondary and Region 1 DR primary cluster.
- Generate a secondary activation token from Region 1 DR primary.
- Copy the generated
wrapping_token, you will need it in the next step to update the primary for Region 2 DR secondary. - Update the primary of Region 2 DR secondary using the batch DR operation token and the secondary activation token from Region 1 DR primary.
- Enable load balancer.
- Enable network load balancer to Region 1 DR primary and Region 2 DR secondary.
- Enable global load balancer.
- Notify Vault consumers and stakeholders Vault is back online.