Standard operational procedures
In this section, we will discuss the standard operational procedures for Vault Enterprise (the self-hosted variant of Vault). These procedures include data backup, restoration, and system upgrades. Mastering these processes is crucial for ensuring data integrity, disaster recovery readiness, and the ability to access the latest features and security enhancements. These standard procedures are fundamental for effectively managing your Vault Enterprise deployment.
Backup standard procedure
Note
On HCP Vault, snapshot functionality is managed by the HCP control plane. On starter tier and above clusters HashiCorp performs automated daily snapshots, with the option for a customer-initiated on-demand snapshot. See HCP Vault Operations Tasks.
The objective of this section is to provide a set of standard operating procedures (SOP) for backing up a Vault cluster. It protects your Vault cluster against data corruption or sabotage of which disaster recovery replication might not be able to protect against.
Prerequisites
The following prerequisite steps and knowledge are required in order to backup a Vault cluster. All of the following are required to understand or carry out before attempting to take a backup or restore of Vault.
- Working knowledge of Vault: Some working knowledge of Vault is required in order to follow these SOPs.
- Vault cluster configuration as defined in our Vault with Integrated Storage Reference Architecture(opens in new tab).
- Vault is initialized: This SOP assumes you have already initialized Vault, keyholders are available with access to the unseal keys for each, that you have access to tokens with sufficient privileges for both clusters and encrypted data is stored in the storage backend.
Automated backup procedure for Vault with disaster recovery replication enabled
Enable automated snapshots on the primary cluster with the following command, following the instructions on the Raft Integrated Storage Documentation(opens in new tab) and using the options specified on the API Documentation(opens in new tab).
vault write sys/storage/raft/snapshot-auto/config/[:name] [options]
Restoring a Vault Enterprise cluster
The objective of this section is to provide a set of standard operating procedures for restoring a Vault cluster from a snapshot.
Note
These procedures specifically apply to Vault clusters that use the integrated storage backend.
While typically you would rely on your DR secondary cluster to protect against data loss, there are cases that disaster recovery replication cannot safeguard against, such as data corruption or malicious data manipulation. In these cases, snapshots are the only source of data you will be able to trust when attempting to restore service.
Restore procedure for Vault with disaster recovery replication enabled
- Prepare and initialize the new restored Vault cluster. Initialize the cluster, then log in with the new root token that was generated during initialization. Note that these keys and tokens are only temporary; the original unseal keys will be needed following restore.
- Copy the snapshot file onto the new cluster. Begin the snapshot restore with the following command.
vault operator raft snapshot restore -force <backup.snap>
Replace backup.snap with the filename of your snapshot file.
Because the snapshot you are restoring is from a different cluster, the unseal keys of the new cluster will not be consistent with the snapshot data. In cases like this, you must specify the -force flag for the snapshot restore to succeed.
Caution: you can safely use -force when restoring a snapshot from a system using Shamir seal. After the restore, the original storage entry for the root key will be available, allowing the original cluster's unseal keys to decrypt it. However, with autounseal, it is crucial to use the same seal configuration for the new cluster as the one used for the cluster being restored. If not, data decryption will not be possible after the restore, and using -force will disable a valuable safeguard.
- Once the snapshot restore is complete, unseal the Vault cluster again using the following command.
vault operator unseal <unseal_key>
Vault Enterprise upgrade
Note
On HCP Vault, upgrades are managed by the HCP control plane. See HCP Vault Operations Tasks.
When it comes to upgrading HashiCorp Vault, it is essential to follow well-defined operating procedures to ensure a smooth transition and minimal disruption. Vault upgrades are crucial for security and performance enhancements, but they can also be complex. In this regard, understanding the correct steps and best practices is vital. Ensure the run book is understood by multiple staff in the Platform Team and tested by someone who is not the author to ensure it is fully understandable.
Autopilot
HashiCorp highly recommends that you utilize the autopilot upgrade feature, as it greatly streamlines and simplifies the upgrade process. Autopilot is purpose-built to minimize administrative involvement and reduce downtime, making upgrades smoother. It synchronizes all data to new nodes, and it accomplishes this through snapshots instead of the replication subsystem. This approach is often faster and more comprehensive. Raft seamlessly manages this process, sparing you the need to delve into the technicalities. Another benefit of utilizing autopilot is that there is less of a need to expend resources closely monitoring traffic during upgrades, as this feature comes with many safety checks. This can lead to fewer potential losses in terms of both time and data. Additionally, you can leverage Terraform for setting up and deploying configurations and Packer for creating new nodes from templates. Autopilot ensures that Vault executes parts of the upgrade process in the correct order, resulting in minimal downtime.
When using Vault's Autopilot upgrade function, it's important to be mindful of a couple key considerations. Autopilot simplifies the safe transition of leadership to the new nodes, while demoting the old ones so as not to impact quorum. However, this ease of provisioning should be monitored to ensure it aligns with your infrastructure requirements.
Autopilot does not automatically manage the removal of old nodes. You should always manually decommission outdated nodes once an upgrade is successfully completed to prevent resource inefficiencies.
The default autopilot configurations are suitable for most scenarios. Unless you have a specific reason for doing so, it is advised against tuning the autopilot config. Picking inappropriate values can lead to difficult-to-debug problems. These default configurations are best suited for relatively static clusters, such as those deployed on manually provisioned VMs. However, if you are operating in a more dynamic environment, like Kubernetes or behind an auto scaling group or equivalent, tuning may be beneficial.
If autopilot is not available to you, please refer to the appendix.
How to upgrade Vault in an AWS auto scaling group with automated upgrades
Vault autopilot enables you to automatically upgrade a cluster of Vault nodes to a new version as updated nodes join the cluster. This how-to walks through the steps necessary to implement automated upgrades in an AWS auto scaling group (ASG).
Prerequisites
A basic knowledge of AWS Auto Scaling(opens in new tab), including scale-in protection(opens in new tab).
A general understanding of how Vault upgrades work(opens in new tab).
An AWS Auto Scaling group(opens in new tab) containing a Vault cluster running Vault Enterprise 1.11.0 or later.
Upgrade migration must not be disabled on the cluster. Vault Enterprise enables automated upgrade migrations by default. You can check the value of this parameter by running the following command.
$ vault operator raft autopilot get-config | grep 'Upgrade Migration'Output.
Disable Upgrade Migration falseIf upgrade migration is disabled, you can re-enable it by running the following command:
$ vault operator raft autopilot set-config -disable-upgrade-migration=true
Procedure
- In your AWS account, create a launch template(opens in new tab) that can create new instances with the desired new version of Vault. This can be accomplished by using an AMI with Vault already installed, or via a userdata script that installs Vault at boot time.
- Configure the ASG for your Vault cluster to use the new launch template. Once the new launch template is in place, future instances created by the ASG will be created using the new version of Vault. Existing instances will not be affected.
- Update the ASG by changing the desired capacity count to at least double the current number of nodes. For example, if 3 nodes are currently deployed, change the desired capacity to
6.
Note
The number of new nodes running the target version of Vault must be equal to or greater than the number of existing nodes before the autopilot process will begin promoting new nodes to voters.
The ASG will begin creating additional instances up to the desired capacity. Once enough nodes running the target version have joined the cluster, the upgrade migration process should start. Monitor this process using the following command:
$ watch -n 0.5 'curl \ -H "X-Vault-Token: $VAULT_TOKEN" \ $VAULT_ADDR/v1/sys/storage/raft/autopilot/state \ | jq -r ".data.upgrade_info"'Continue to monitor the output until the
statusfield readsawait-server-removal. The output will look similar to the following:{ "other_version_non_voters": [ "vault_2", "vault_3", "vault_4" ], "status": "await-server-removal", "target_version": "1.12.0.1", "target_version_voters": [ "vault_5", "vault_6", "vault_7" ] }Collect the node ids from this output to refer to in subsequent steps.
other_version_non_voterscontains the list of nodes running the old version of Vault, which have been demoted to non-voting status.target_version_voterscontains the list of nodes running the new version of Vault, which have been promoted to voting status.Remove the nodes running the old version of Vault from the cluster. For each node that needs to be removed, run the following command:
$ vault operator raft remove-peer <node id>Temporarily enable scale-in protection for each instance running the new version of Vault. This will prevent the ASG from destroying the new nodes during scale-in events. Follow the steps found at Change Scale-in Protection for an Instance(opens in new tab) in the AWS Documentation to enable scale-in protection. You can verify that protection is enabled by checking the
Protected Fromcolumn in the AWS management console.
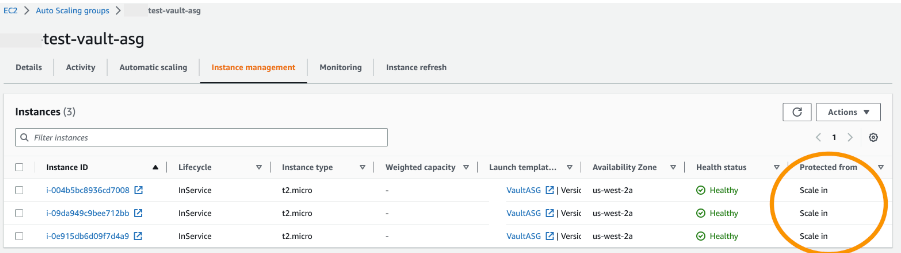
Update the ASG again, this time reducing the desired capacity count to its original value. The ASG will begin terminating instances. Instances with scale-in protection enabled will be protected from termination, while instances without protection will be terminated. When this process is complete, all old nodes should be removed from the cluster.
Verify that your Vault cluster is healthy and that the upgrade was successful by running the following command:
$ vault statusVerify that the version number matches the target version of Vault, and that
Sealedisfalse.Remove scale-in protection from the remaining instances. Follow the steps found at Change scale-in protection for an instance(opens in new tab) in the AWS Documentation to disable scale-in protection.