Detailed design
Core design requirements
This section takes the recommended architecture from the above section and provides more detail on each component of the architecture. Carefully review this section to identify all technical and personnel requirements before moving on to implementation.
Compute
This section contains specific hardware capacity recommendations, network requirements, and additional infrastructure considerations.
Sizing
Every hosting environment is different, and every customer's Vault usage profile is different. These recommendations should only serve as a starting point, from which each customer's operations staff may observe and adjust to meet the unique needs of each deployment. For more information, refer to the Vault Reference Architecture section on Sizing For Vault Servers(opens in new tab).
Sizing recommendations have been divided into two common cluster sizes: small, and large. Small clusters would be appropriate for most initial production deployments or for development and testing environments. Large clusters are production environments with a consistently high workload. That might be a large number of transactions, a large number of secrets, or a combination of the two.
| Size | CPU | Memory | Disk capacity | Disk IO | Disk throughput |
|---|---|---|---|---|---|
| Small | 2-4 cores | 8-16 GB RAM | 100+ GB | 3000+ IOPS | 75+ MB/s |
| Large | 4-8 cores | 32-64 GB RAM | 200+ GB | 10000+ IOPS | 250+ MB/s |
For a mapping of these requirements to specific instance types for each cloud provider, refer to the cloud-focused sections below.
Hardware considerations
In general, CPU and storage performance requirements will depend on the customer's exact usage profile (e.g. types of requests, average request rate, and peak request rate). Memory requirements depend on the total size of data stored in memory and should be sized according to that data.
Note
For predictable performance on cloud providers, avoid burstable CPU and storage options, such as AWS t2 and t3 instance types. Performance for these types of instances may degrade rapidly under continuous load.
When using integrated storage, Vault servers should have a high-performance hard disk subsystem capable of up to 10000+ IOPS and 250+ MB/s disk throughput. Many vault operations (such as login requests) require multiple disk writes. When many secrets are generated or rotated frequently, Vault also needs to flush this data to disk. In both cases, the use of slower storage systems will negatively impact performance(opens in new tab).
Hashicorp strongly recommends configuring Vault with audit logging enabled, as well as telemetry for diagnostic purposes. The configuration of these components is covered in Vault: Operating Guide for Adoption. The impact of the additional storage I/O from audit logging will vary depending on your particular pattern of requests.
Tip
Always write audit logs to a separate disk. This approach reduces the risk of performance bottlenecks that can occur when audit logs compete for resources with other system processes.
Warning
Configure multiple audit devices to enhance reliability and redundancy. If one device encounters issues, others continue to function, ensuring continuous, uninterrupted logging. This setup is crucial for maintaining robust audit trails and supporting both effective troubleshooting and security monitoring. Vault Enterprise will stop operations immediately should all audit devices fail.
Networking
Vault requires node interconnection between AZs, client redirect logic, and load balancers configured with TLS passthrough to connect clients to clusters.
Note
For security reasons, Vault clusters should not be exposed to the public internet.
Node interconnectivity requires low latency (around 8ms(opens in new tab)) to replicate secrets across the integrated storage backend, as well as to efficiently route client write requests from standby nodes to the active node. These nodes are also fronted by Layer 4 load balancers, which permit end-to-end TLS communication.
Network rules must allow Vault to communicate across TCP ports designated for API and intracluster traffic. Vault nodes should be deployed in private subnets. Network address translation (NAT) devices should be deployed in public subnets to allow VMs/instances to retrieve critical security updates via egress Internet traffic.
Availability zones
This Validated Design uses 3 availability zones, with 2 nodes per availability zone.
In order for cluster members to stay properly in sync, network latency between availability zones should be less than eight milliseconds (8 ms).
Network connectivity
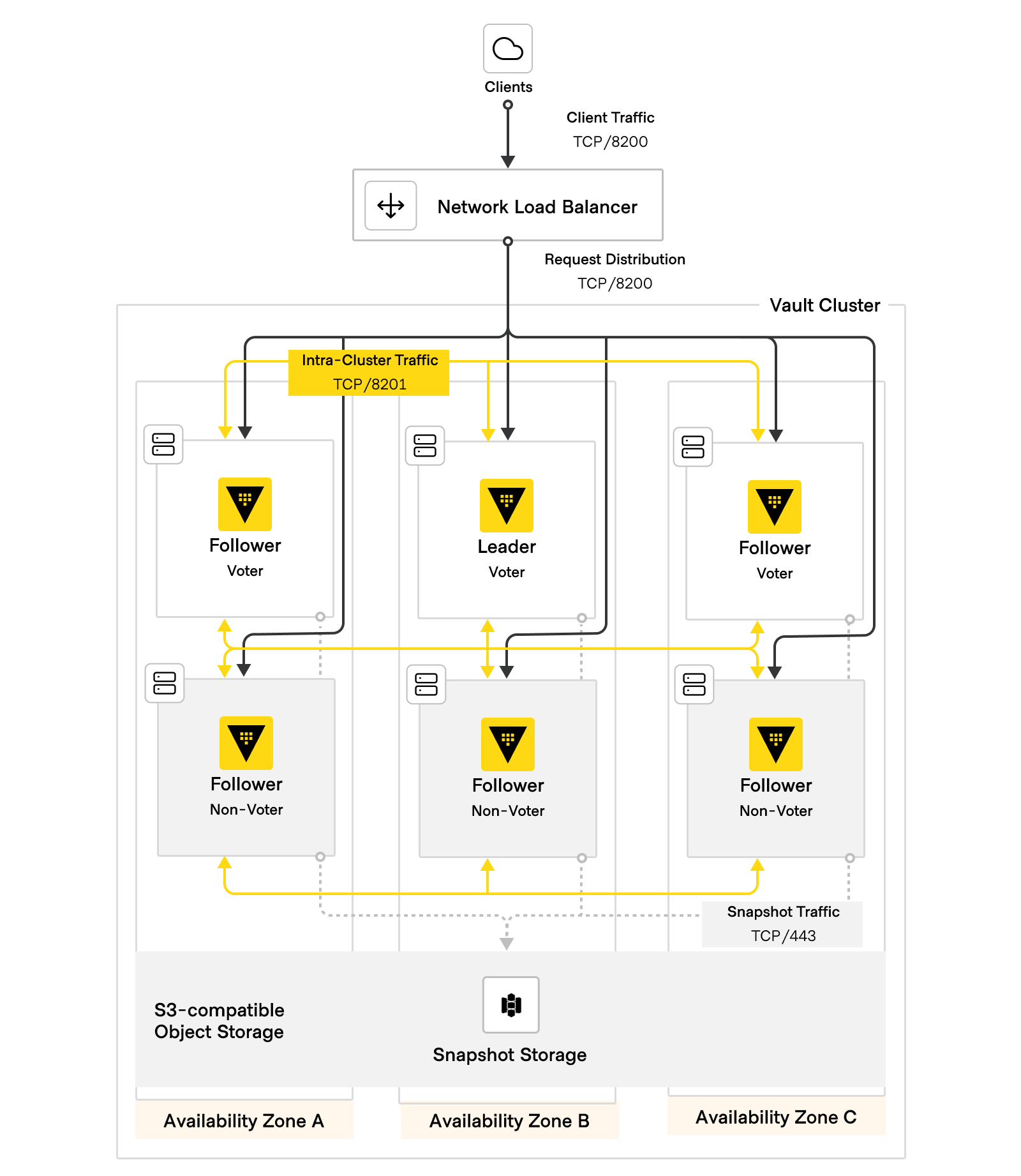 Figure 5: HVD Vault networking diagram
Figure 5: HVD Vault networking diagram
The following table outlines the minimum network connectivity requirements for Vault cluster nodes. You may also need to grant the Vault servers outbound access to additional services that live elsewhere, either within your own internal network or via the Internet. Examples may include:
- Authentication and secret provider backends, such as AWS or a Kubernetes cluster.
- NTP, for maintaining consistent time between nodes.
- Remote log handlers, such as a Splunk or ELK environment.
- Metrics collection, such as Prometheus; etc.
| Source | Destination | Port | Protocol | Direction | Purpose |
|---|---|---|---|---|---|
| Client machines/administration | Load balancer | 8200 | tcp | incoming | Request distribution |
| Load balancer | Vault servers | 8200 | tcp | incoming | Vault API; api_addr |
| Vault servers | Vault servers | 8200 | tcp | bidirectional | Cluster bootstrapping |
| Vault servers | Vault servers | 8201 | tcp | bidirectional | Raft, replication, request forwarding; cluster_addr |
| Vault servers | External systems | various | various | various | External APIs |
Vault generally should not be exposed to inbound traffic via a publicly-accessible endpoint. This is to minimize both the risk of exposing secrets as well as the risk of denial-of-service attacks. Wherever possible, access to the Vault API should be limited to the networks where Vault needs to be accessed.
Here is an overview of an example write transaction to Vault:
- Clients make HTTPS requests to Vault via the load balancer endpoint over port
8200. - The load balancer selects a target and forwards the request to one of the Vault servers in the cluster via port
8200. - TLS is terminated at the Vault server that receives the request.
- If the node that receives the request is not the active node, the request is then forwarded from the standby node to the active node via port 8201 using the IP address known from the
config.hcl. - The active node receives the request and performs the write operation.
- The node that received the request sends a response to the client. This is regardless of whether it is the active node – clients are not aware of whether the request had been forwarded.
- All data written to the active node is then replicated to its standby nodes via port
8201.
Note
The amount of network bandwidth used by Vault will depend entirely on the specific customer's usage patterns. In many cases, even a high request volume will not translate to a large amount of network bandwidth consumption. It's also important to consider bandwidth requirements to other external systems, such as monitoring and logging collectors.
Traffic encryption
Every segment of Vault-related network traffic should be encrypted in transit using TLS over HTTPS. This includes communication from clients to the Vault servers, as well as communication between cluster members.
You will need to create a standard X.509 public certificate from an existing trusted certificate authority internal to your organization. This certificate will represent the Vault cluster, and will be served by each Vault server in the cluster. Along with the certificate itself (vault-public.pub), you will also need to supply the certificate's private key (vault-private.key), as well as a bundle file from the certificate authority used to generate the certificate (ca.pub). These files are referenced in the implementation section of this document.
Vault also encrypts server-to-server communication, which requires no additional configuration. Vault automatically negotiates an mTLS connection between servers when new members join the cluster.
DNS
Internally, Vault nodes do not use DNS names to talk to other members of the cluster, relying instead on IP addresses. However, you will need to configure a DNS record that resolves to the IP address hosting your load balancer configuration. This guide uses vault.domain as the example value to refer to this DNS record in later sections.
Load balancing
Use a TCP-based (layer 4) load balancer to distribute incoming requests across multiple Vault nodes within a cluster. Configure the load balancer to listen on port 8200/tcp and forward requests to all Vault nodes in the cluster on port 8200/tcp. All healthy nodes in the cluster should be able to receive requests in this way, including standby nodes (i.e. followers) and nodes configured as non-voters.
Tip
While this guide uses the default port 8200/tcp for the load balancer, using another port (such as 443/tcp) is also supported, and is a common practice for Vault deployments.
TLS passthrough
Configure the load balancer to use TLS passthrough, rather than terminating the TLS connection at the load balancer. This keeps the traffic end-to-end encrypted from the client to the Vault nodes, removing even the load balancer as a possible attack vector.
Health check
Each Vault node provides a health check API endpoint at /v1/sys/health. HTTPS-based health checks provide a deeper check than simply checking the TCP port.
Configure your load balancer to perform a health check to all Vault nodes in a cluster by using the path /v1/sys/health?perfstandbyok=true, with an expected status code of 200. By default, only a leader node returns a 200 status code. Setting the perfstandbyok parameter to true instead will direct all nodes to return a 200 status code, including non-leader nodes (also known as performance standby nodes(opens in new tab)). Configuring the health check in this way enables the load balancer to spread client read requests to all nodes in the cluster, while write requests sent to performance standby nodes will still be redirected to the leader node using request forwarding(opens in new tab).
For specific details on all query options and response codes and their meanings, refer to the HashiCorp Vault Documentation on the /sys/health API endpoint(opens in new tab).
Tip
If possible, use a load balancer that supports both TLS passthrough and HTTPS-based health checks. AWS NLB, F5 BigIP, Citrix ADC, and HAProxy are just a few examples of load balancers that support this combination of functionality.
Some load balancers, such as Nginx, do not allow for both TLS passthrough and the use of HTTPS-based health checks. If another type of load balancer cannot be used in your environment, you can still use a simple port-based check instead. Please note that port-based health checks are a more limited type of check, and may not detect issues that an HTTPS-based check would.
Software
To deploy production Vault, this Validated Design only requires the Vault Enterprise software binaries to be installed on the Vault servers.
The Vault process should not be run as root. Instead, a dedicated user should be created and used both to run the Vault service as well as to protect the files used by and created by Vault. Because of this, extra steps will be needed to grant this user access to the mlock() system call, which is used to protect data in memory from being swapped to disk.
For systemd-based OSes, you can specify this capability in the Vault systemd unit file:
[Unit]
Description=Vault service
Requires=network-online.target
After=network-online.target
[Service]
User=vault
Group=vault
ExecStartPre=/sbin/setcap 'cap_ipc_lock=+ep' $(readlink -f $(which vault))
ExecStart=/usr/local/bin/vault server -config /etc/vault.d/config.hcl
Capabilities=CAP_IPC_LOCK+ep
CapabilityBoundingSet=CAP_SYSLOG CAP_IPC_LOCK
...
- The
ExecStartPreline allowsmlock()to be used by the Vault binary. - The
CapabilitiesandCapabilityBoundingSetlines allow the system call to be used by the Vault process.
By taking both of these steps, you will have eliminated an additional attack vector for Vault.
Vault license
Your Vault Enterprise license must be deployed on every Vault node in order for the Vault process to start. The implementation section has more details on how to autoload the license at each Vault start time.
Storage
Data storage
Use integrated storage as the storage backend for Vault. Vault's persistent data storage lives on the Vault servers.
Backups
Integrated storage provides an Automated Snapshots(opens in new tab) feature, which enables you to perform backups of your data within Vault. Unlike OS- or volume-based snapshots, Vault automated snapshots only capture the integrated storage dataset. This ensures data integrity and consistency when recovering Vault.
To store your snapshots, you can either use an object store, such as Amazon S3, or a durable remote filesystem, such as NFS. The procedure for configuring automated snapshots is detailed in Vault: Operating Guide for Adoption.
Configuration
This section covers the various sections of your Vault configuration file. This file is referenced each time the Vault server process is started.
The configuration file is made up of a number of different stanzas. Below you will find required fields for each stanza. In some cases the fields will contain the recommended values, but others will be dependent on your particular environment. In those cases, take note of what the relevant values are, as you will need them during the installation process as detailed in the Implementation section.
listener Stanza
This stanza defines the listener configuration for Vault. It specifies the address and port on which Vault will listen for incoming connections, as well as the TLS certificate and key files to use for TLS termination.
listener "tcp" {
address = "0.0.0.0:8200"
tls_cert_file = "/etc/vault.d/server.crt"
tls_key_file = "/etc/vault.d/server.key"
tls_client_ca_file = "/etc/vault.d/ca.pub"
}
tls_cert_file specifies the path to the server's TLS certificate file.
tls_key_file specifies the path to the server's private key file.
tls_client_ca_file specifies the path to the certificate authority file, which is used to verify client certificates if you want to enforce client-side authentication.
Tip
The CA file listed in tls_client_ca_file is only used as part of client-based authentication, and it is not used to validate the web server itself.
Tip
If you wish to include an issuer CA certificate as part of the certificate chain, you can concatenate the certificate into tls_cert_file.
storage stanza
This stanza defines integrated storage (aka raft) as the Vault storage method, defines where Vault's data will be stored on disk for each server, and lists the other servers that will be members of the cluster.
storage "raft" {
path = "/var/lib/vault/data"
node_id = "vault1"
retry_join {
leader_api_addr = "https://vault-1.domain:8200"
leader_ca_cert_file = "/etc/vault.d/ca.pub"
leader_client_cert_file = "/etc/vault.d/vault-public.pub"
leader_client_key_file = "/etc/vault.d/vault-private.key"
leader_tls_servername = "vault.domain"
}
retry_join {
leader_api_addr = "https://vault-2.domain:8200"
leader_ca_cert_file = "/etc/vault.d/ca.pub"
leader_client_cert_file = "/etc/vault.d/vault-public.pub"
leader_client_key_file = "/etc/vault.d/vault-private.key"
leader_tls_servername = "vault.domain"
}
retry_join {
leader_api_addr = "https://vault-3.domain:8200"
leader_ca_cert_file = "/etc/vault.d/ca.pub"
leader_client_cert_file = "/etc/vault.d/vault-public.pub"
leader_client_key_file = "/etc/vault.d/vault-private.key"
leader_tls_servername = "vault.domain"
}
...
}
path: Specifies the directory where Vault should store its data on disk.node_id: A unique identifier for the node within the Raft cluster. Can be any string.retry_join: This block configures Vault nodes to auto-join the Raft cluster on startup.
The retry_join stanzas identify other Vault nodes in the cluster. If the connection details for all nodes in the cluster are known in advance, you can use these stanzas to facilitate automatic joining of the nodes to the Raft cluster. Each stanza declares identifying details of a particular node. Upon initialization of one node as the leader, the remaining nodes will use this configuration to locate and connect to the leader node, thus forming the cluster. For more information on the retry_join stanza, refer to the HashiCorp Vault documentation on Integrated Storage(opens in new tab).
Tip
In practice, each node's configuration should include the same stanzas for simplicity. There is no need for a node to exclude itself in its configuration.
seal stanza
Your Vault config should include auto-unseal configuration via the seal stanza. Manual unsealing using the Shamir secret sharing algorithm does not require the use of this stanza.
Example of auto-unseal using AWS KMS:
seal "awskms" {
region = "us-west-2"
kms_key_id = "abcd1234-a123-456a-a12b-a123b4cd56ef"
}
regionspecifies the AWS region where the KMS key resides.kms_key_idspecifies the ID of the AWS KMS key that will be used for auto-unsealing.
Example of auto-unseal using PKCS11 (HSM)(opens in new tab):
seal "pkcs11" {
lib = "/usr/vault/lib/libCryptoki2_64.so"
slot = "2305843009213693953"
pin = "AAAA-BBBB-CCCC-DDDD"
key_label = "vault-hsm-key"
hmac_key_label = "vault-hsm-hmac-key"
}
lib: Path to the PKCS #11 library on the virtual machine where Vault Enterprise is installed.slot: The slot number to use.pin: PKCS #11 PIN for login.key_label: Defines the label of the key you want to use.hmac_key_label: Defines the label of the key you want to use for HMAC.
PKCS#11 authentication occurs via a slot number and PIN. In practice, because the PIN is not required to be numeric (and some HSMs require more complex PINs), this behaves like a username and password.
Like a username and password, these values should be protected. If they are stored in Vault's configuration file (like the stanza example above), read access to the file should be tightly controlled to appropriate users.
Rather than storing these values into Vault's configuration file, they can also be supplied via environment variables(opens in new tab).
Note
Your HSM's configuration may require additional fields, depending on the device. Consult the Vault HSM seal documentation and your HSM documentation as needed.
telemetry stanza
The Vault server process collects various runtime metrics about the performance of different libraries and subsystems. Telemetry from Vault must be streamed and stored in metrics aggregation software to monitor Vault and collect durable metrics. For more information, see the HashiCorp Vault documentation on Telemetry(opens in new tab).
The telemetry stanza defines how metrics will be made available to your telemetry platform. If you do not already have an existing metrics platform, we recommend using Prometheus, which has a good balance of simplicity of configuration and scalability.
Example of a telemetry configuration using Prometheus:
telemetry {
disable_hostname = true
prometheus_retention_time = "12h"
}
prometheus_retention_time(string: "24h"): Specifies the amount of time that Prometheus metrics are retained in memory. Setting this to0will disable Prometheus telemetry.disable_hostname(boolean): prevent metrics from being prefixed with hostname.
Warning
By default, metrics are be scraped from the leader node, which may change over the lifetime of a cluster. If disable_hostname is not set to true, metrics will be prefixed with the hostname of the leader node, which will cause metrics to be lost when the leader changes.
Additional guidance about collecting metrics via Prometheus can be found in Vault: Operating Guide for Adoption. For more information, see the HashiCorp Vault documentation on Monitoring Telemetry using Grafana and Prometheus(opens in new tab).
Unseal and recovery keys
Vault encrypts data with an encryption key. That encryption key is further encrypted with a second key, known as the root key. At Vault initialization time, you can choose to split the root key into a number of key shares using Shamir's secret sharing algorithm. When initializing Vault with the Shamir seal, the generated key shares are called unseal keys. When initializing Vault with auto-seal or HSM, the key shares are known as recovery keys. There are important differences between the two.
Both unseal keys and recovery keys can authorize Vault to perform certain operations, such as generating a new root key. However, only unseal keys are able to decrypt the root key and unseal Vault. Recovery keys cannot decrypt the root key, and thus are not sufficient to unseal Vault if the Auto Unseal mechanism is not working. They are purely an authorization mechanism.
Warning
Using auto unseal creates a strict Vault lifecycle dependency on the underlying seal mechanism. This means that if the seal mechanism (such as the cloud KMS key) becomes unavailable or is deleted, then there is no ability to recover access to the Vault cluster until the mechanism is available again. If the seal mechanism or its keys are permanently deleted, then the Vault cluster cannot be recovered, even from backups.
For more information, see the HashiCorp Vault documentation on Seal Concepts(opens in new tab).
Key share encryption
When you initialize Vault, it returns hexadecimal-encoded or base64-encoded representations of the key shares and initial root token value in plaintext by default. Vault can encrypt the key shares and initial root token value at initialization time with user-supplied public keys generated from any RFC 4880 compliant PGP software, such as GNU Privacy Guard (GPG).
By initializing Vault with the pgp-keys and root-token-pgp-key options, it
- Encrypts the unseal keys and root token value with the specified GPG public keys.
- Base64 encodes the encrypted values.
- Outputs those values instead of plaintext values.
Before installing Vault, choose the individuals who will be participating in this process. Each individual will need to create their own PGP-compliant public key that will be used in the encryption process. Please note that PGP encryption is tied to the individual user and relies on their private key, which may not be well secured or reliably stored. You will create these keys later as part of the implementation steps.
Key share threshold
Vault requires a threshold of unseal or recovery key shares to authorize certain vital operations in Vault. When generated, these key shares should be distributed amongst a chosen set of trusted individuals. However, consider the real-world implications of having humans responsible for providing key share data.
If a member of the team departs the organization or is otherwise severed, their portion of the recovery key will not be accessible, especially if it is PGP encrypted. Over time, an organization will likely experience personnel attrition, thereby losing a threshold of key shares to perform vital recovery operations.
Operators should plan in advance for how many key shares they want Vault to generate during initialization, and how many of those key shares are required to meet the threshold. Both options are configurable when initializing Vault. By default, Vault will create 5 key shares, with a threshold of 3 required to reconstitute the unseal or recovery key.
Rekeying and rotating Vault
In addition to configuring Vault to generate a higher number of recovery key shares, Vault operators should also define a cadence by which they rekey Vault and rotate its encryption key. Rekeying(opens in new tab) is a manual process where Vault is instructed to regenerate the root key and its key shares. Common events that can warrant a rekey include:
- Someone joins or leaves the organization.
- Security wants to change the number of shares or threshold.
- Compliance mandates the keys be rotated at a regular interval.
Rekeying the Vault requires a threshold number of unseal keys. Before continuing, you should ensure enough unseal key holders are available to assist with the rekeying to match the threshold configured when the keys were issued.
The standard Vault recommendation for unseal key shares/recovery key shares has historically been 5 key shares with a threshold of 3 to do sensitive actions. This recommendation comes from the competing priorities of making these actions simple to perform, but minimizing the likelihood that they can be performed by only one user without checks or balances. As long as you schedule a regular interval to rekey your keys and promptly replace any keyholders that leave your team and rekey the keys at that point, this recommendation is likely sufficient for most customers, with some limited caveats.
Tip
If you are using a Shamir seal instead of an auto-unseal mechanism, you may wish to specify more key shares without raising your threshold so that in the event that your Vault seals at an inconvenient time, you have a higher probability of rapidly paging your keyholders and unsealing Vault. If your Vault cluster has a large number of admin teams managing it, and a large pool of administrators that work with it, you may want to examine having more keyshares, or the possibility of having a higher threshold if sensitive actions need to be validated by more teams.
In addition to rekeying the root key, there may be an independent desire to rotate the underlying encryption key Vault uses to encrypt data at rest. Unlike rekeying the Vault, rotating Vault's encryption key does not require a quorum of unseal keys. Anyone with the proper permissions in Vault can perform the encryption key rotation.
Compute
Each Vault node in a cluster resides on a separate EC2 instance (shared or dedicated tenancy is fine). A single Vault cluster lives in a single AWS region, with nodes deployed across all availability zones (AZs). This design leverages Vault Enterprise Redundancy Zones(opens in new tab), and deploys 6 nodes in total across 3 AZs. Within each AZ, one node will be configured as a voting node, while the other will be configured as a non-voting node.
Operating systems
The Validated Design Terraform module uses Ubuntu 22.04.
Sizing
On AWS, you can use m5.2xlarge or m5.4xlarge instance types to supply the recommended amounts of vCPU and RAM(opens in new tab) for Vault.
Create new gp3 volumes configured with desired disk throughput and IOPS for your expected workload. If you are unsure of your workload requirements, your HashiCorp account team can help you evaluate your use case and provide specific guidance.
Tip
Instance types from later instance families can also be used, provided that they meet or exceed the above resource recommendations.
Autoscaling
Note
This architecture design above only for ease of deployment and self-healing, but not for scaling. Vault itself is not natively elastic.
To deploy these instances, the HVD Terraform module will create cloud objects for auto-scaling in the respective cloud with its count set to min = 1, max = 6, desired = 6. This allows for logging alarms on the network load balancer (NLB) target group to trigger behavior that terminates and relaunches instances in the VM group.
Networking
Private network
The Validated Design module creates a new VPC and deploys a number of resources:
- One private and one public subnet for each AZ (total of 6).
- Private and public route tables.
- One NAT gateway per subnet, each paired with an elastic IP (total of 3 NATs and 3 eIPs).
- One Internet gateway.
- Ingress and egress security groups (total of 2).
Subnets
The Validated Design deploys 3 private subnets and 3 public subnets across 3 AZs. The Vault service is not exposed to the public Internet, so the module deploys VM instances into the private subnets.
NAT Gateway instances are deployed in the public subnets. The design also deploys an Internet gateway into the VPC.
Routing
Along with creating subnets, NAT gateways, security groups, and load balancers, the Validated Design defines routes for connecting resources together. VPC route tables
- define ingress and egress routes among all of the private subnets for intra-node communication.
- Allow ingress and egress traffic from the private subnets to the NAT gateways (public subnets) for communication with the NLB, as well as services such as S3, blob storage and GCS.
- Define the egress route between NAT gateways and the Internet gateway, thereby providing an Internet route for Vault nodes in private subnets.
AWS security groups
The Validated Design does not deploy firewalls or firewall configurations, but it does deploy security groups (SGs). These security groups facilitate instance communication within the Vault cluster and outside of it. One contains ingress-only rules for TCP ports 8200 and 8201, and the other is the VPC-default (unused).
Load balancing
For load balancing in AWS, use a network load balancer (NLB) in front of all Vault cluster nodes, across all subnets. There are NLB listeners each for TCP ports 8200 and 8201. The target groups associated with each of these listeners will both contain the full set of all cluster nodes.
An HTTPS health check is used for all target groups using the path below.
/v1/sys/health?perfstandbyok=true&activecode=200&performancestandbycode=473
Software
Vault license
Your Vault Enterprise license must be deployed on every Vault node in order for the Vault process to start. When using the included Terraform modules, you will submit your license file as a variable to Terraform, which will base64 encode it and create a new secret with its contents on the respective cloud secrets management service (such as AWS Secrets Manager, Azure KeyVault and Google Secret Manager). As part of the cloud-init process, the license contents will be read from the secrets manager service, decoded, and written to a file on the node at a location that will be autoloaded(opens in new tab) by the Vault service at start time.
Storage
When deploying on public cloud, use the native CSP cloud storage to store automated snapshots. The storage should be deployed in the same region as the compute instances.
Auto-unseal
Operators deploying Vault in a cloud context will leverage the key management service of the respective cloud to generate the key used for auto-unsealing the cluster. The provided Terraform deployment modules will create a customer managed key (CMK) for this purpose, and will reference the ARN path for this key in the seal stanza of the Vault configuration file on each server.
DNS
The Validated Design assumes that you already have a public DNS hosted zone, in Route53 or another DNS service. This is a prerequisite for generating TLS certificates(opens in new tab) that will secure traffic between Vault nodes.
If you intend to use a public cloud for DNS, the HVD module will create
- An A record pointing to the NLB that it also created during deployment
- A failover record pointing to the same target location. You can specify the DNS hostname to the provided Terraform deployment modules, which will create the necessary records in the public cloud DNS service.
Certificates
The provided Terraform deployment modules will read these certificates and base64 encode them before uploading to the public cloud secrets management service for the life of the initial install process.
vault-public.pub- the TLS certificate itselfvault-private.key- the certificate's private keyca.pub- the certificate authority bundle file
IAM
The provided Terraform deployment modules require an IAM role with necessary permissions in order to deploy and manage all required AWS components. The module can create this role on your behalf or use an existing one that you create yourself. If you choose to create the IAM role yourself, ensure the role contains the following policies and permissions:
| Service | Permissions | Resources |
|---|---|---|
| EC2 (for cloud auto-join) | DescribeInstances DescribeVolumes DescribeTags | All (*) |
| SSM* | (Attach AmazonSSMManagedInstanceCore managed policy) | n/a |
| KMS | ReEncrypt GenerateRandom GenerateDataKey* Encrypt DescribeKey Decrypt CreateGrant EnableKeyRotation Vault KMS key | |
| Autoscaling | CompleteLifecycleAction | Vault module ASG hook |
| Secrets Manager | GetSecretValue | Vault license Vault CA bundle Vault public cert Vault private key |
| CloudWatch | PutMetricData PutRetentionPolicy PutLogEvents DescribeLogStreams DescribeLogGroups CreateLogStreams CreateLogGroups | Vault log group |
| S3 | PutObject ListBucket ListBucketVersions GetObject GetBucketLocation DeleteObject | Automated snapshots bucket |