Performance Replication
Overview
As outlined in the Vault: Operating Guide for Adoption, Vault Enterprise supports two types of cluster replication, Disaster Recovery (DR) Replication and Performance Replication (PR).
Vault enterprise performance replication allows for secret management and data encryption across regions, clouds, and data centers. Secrets, authentication methods, authorization policies, encryption keys, and other configuration data is replicated to be active and available in multiple locations in realtime.
A PR secondary cluster replicates everything from the primary except for tokens and leases (for dynamic secrets). Path filters and local mounts can also be used to control which secrets are moved across clusters. A PR secondary cluster can actively serve Vault client requests at the same time as a PR primary cluster. PR replication should primarily be implemented for two use cases:
- Horizontal scaling of “local” writes (token creation and dynamic secrets)
- Reducing latency by serving Vault traffic closer to where clients are deployed
Architecture
Both Vault disaster recovery and performance replication operate on a leader/follower model, wherein a leader cluster (known as a DR or PR primary) is linked to one or more follower (secondary) clusters to which the primary cluster replicates data via a write ahead log (WAL) stream. A given Vault cluster may serve simultaneously in the role of DR primary and PR primary. A cluster can also simultaneously serve as a DR primary and PR secondary. A cluster cannot serve as a DR secondary and PR secondary.
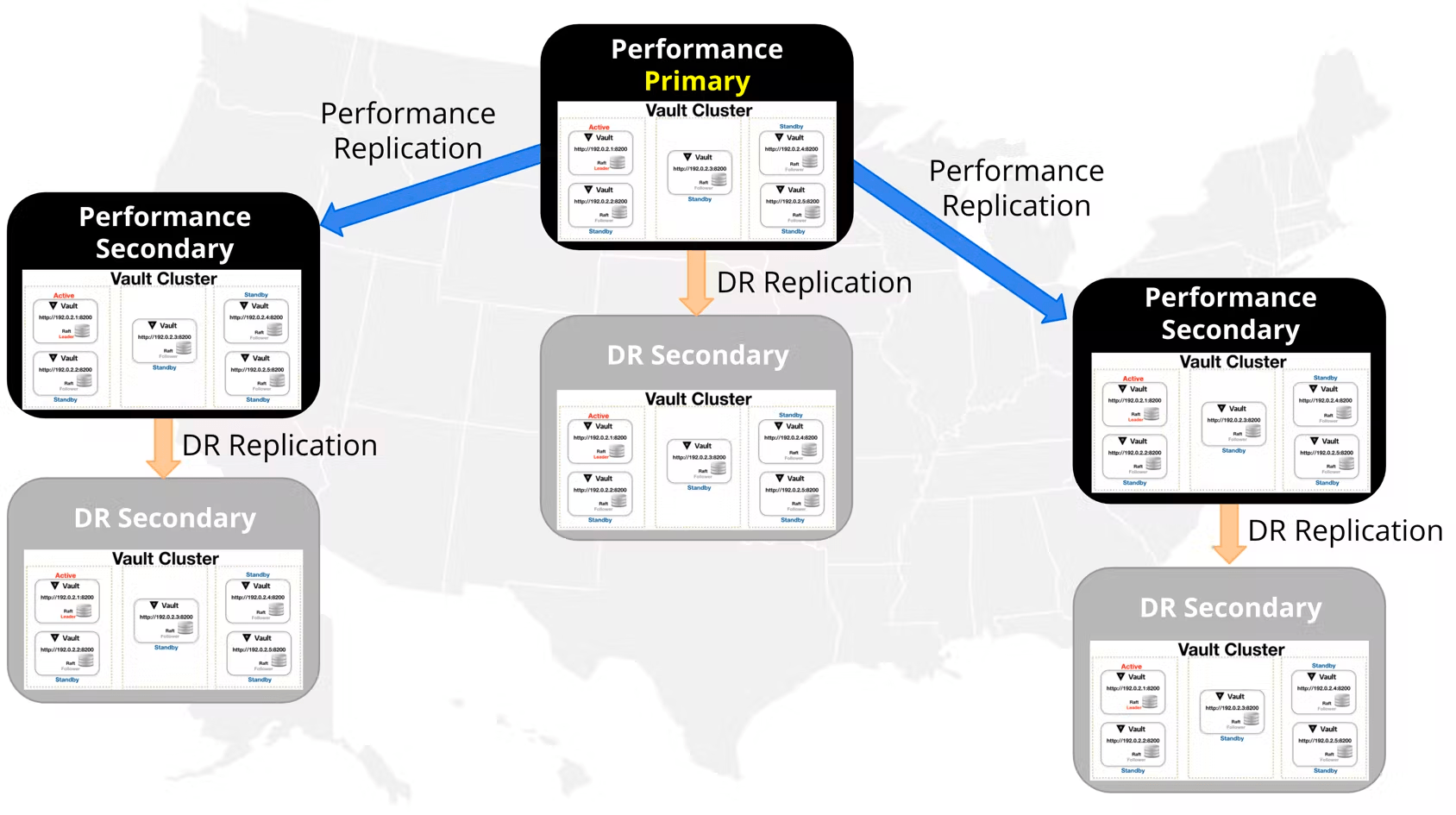
DR and PR replication function in a “one-to-many” architecture. A given DR or PR primary cluster can be associated with multiple DR or PR secondaries. Vault does not place a technical limit on the number of replication relationships that can be established with a given DR or PR primary cluster. However, each replica cluster does add overhead to the active node on the primary cluster, as many transactions must be duplicated to all secondary clusters. The number of PR secondaries that can be paired with a primary cluster without major performance degradation on the primary will ultimately be a function of the specific workload in that Vault environment. We have observed Vault enterprise customers deploying “10s” of PR replicas in production environments successfully.
All communication between primaries and secondaries is end-to-end encrypted with mutually-authenticated TLS sessions, setup via replication tokens which are exchanged during the configuration of the replication relationship.
Each cluster in a DR or PR replication relationship should be configured with an independent auto-unseal mechanism. This means that each secondary cluster does not need to use the same cloud key management service (KMS) unseal key or hardware security module (HSM) unseal key as the primary. Replica clusters that have been deployed across regions can make use of a KMS/HSM unseal key in their local region/datacenter.
When configuring DR or PR replication relationships using auto-unseal mechanisms, the secondary cluster will inherit the recovery keys and recovery configuration of the primary cluster. It is important to ensure that the recovery keys from the primary cluster continue to be kept in a secure manner.
Interaction with Vault clients
Vault Enterprise PR secondary clusters keep track of their own tokens and leases but share the underlying configuration, policies, and supporting secrets (K/V values, encryption keys for transit, etc). If a user action would modify the underlying shared state, the secondary forwards the request to the primary to be handled; this forwarding is fast and is transparent to the client. In most common use cases, the majority of client requests to Vault clusters tend to be read-oriented or localized write requests that can be satisfied by a PR secondary without consulting the primary cluster. Examples of these types of requests include client authentications, reads to the K/V secret backend, encryption/decryption operations in the transit backend, issuance of PKI certificates (depending on engine configuration), and the creation of dynamic secret leases. Because the most common client operations can be handled locally by a PR cluster, this design allows Vault to scale horizontally with the number of secondaries.
Generally, when using Vault performance replication to scale a Vault deployment across multiple regions or data centers, Vault clients should be configured to communicate with their local performance replica cluster, and communications with more than one performance replica cluster will not be needed. In a rare use case where a Vault client needs to communicate with more than one performance replica cluster, you will need to consider the information in the following paragraphs outlining the behavior of Vault tokens when being used across multiple clusters.
Since each PR cluster keeps track of its own tokens and leases, Vault service tokens are not portable between replicated clusters. If a Vault client using service tokens needs to interact with more than one PR cluster, the client will not be able to reuse the same service token on multiple clusters. The client will need to re-authenticate and obtain a new token which is local to the specific PR cluster that it is interacting with.
If a client is using Vault batch tokens, the behavior can be different. Orphan batch tokens contain all the information needed to authenticate to any PR cluster in the replication relationship. Therefore, the same orphan batch token can be reused to authenticate across multiple PR clusters.
Interaction with disaster replication
When planning for a disaster scenario, it is important to understand how the two types of replication modes interact, and how performance replica clusters will behave in a DR promotion scenario.
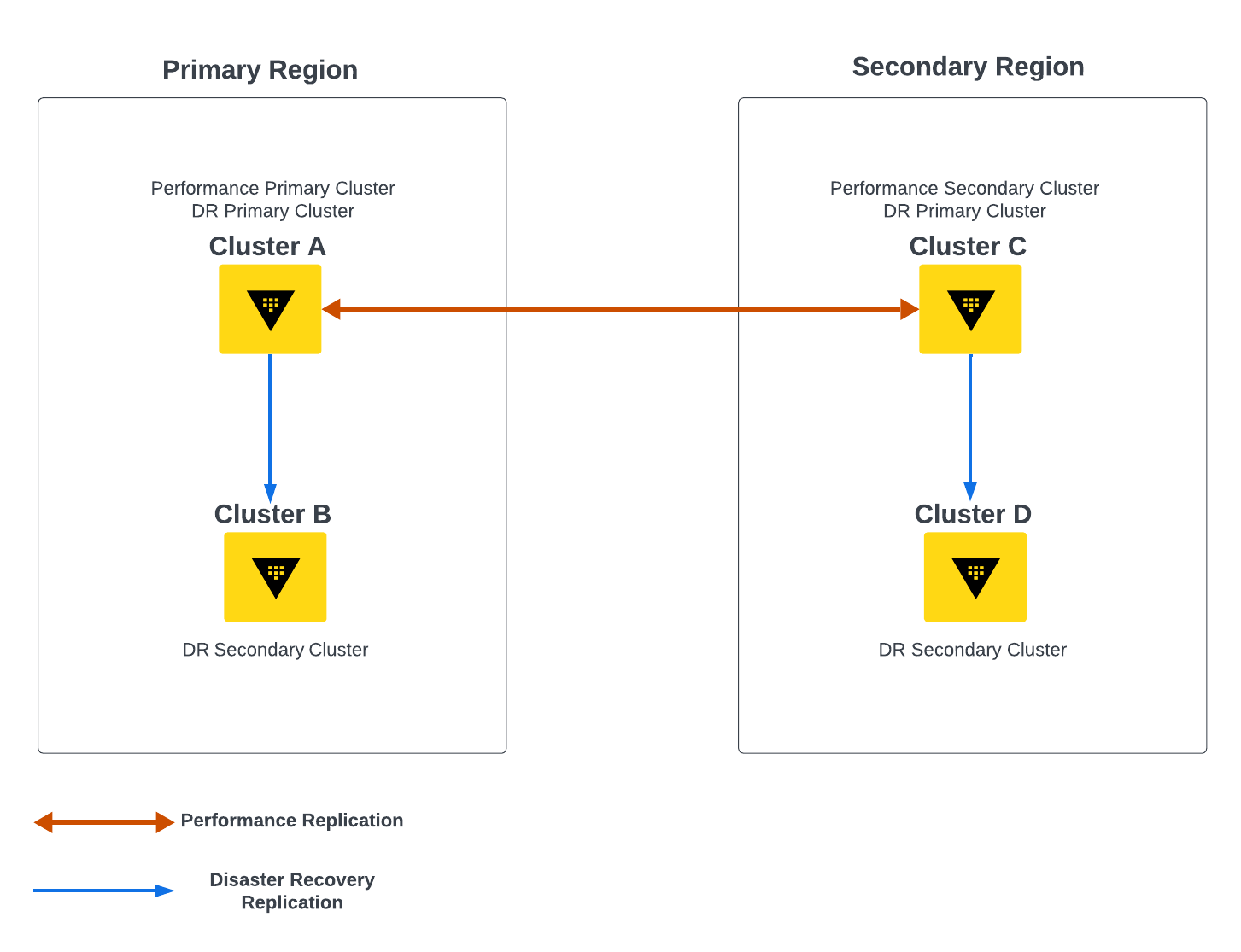
Figure 1. PR and DR Interaction
In the above diagram (Figure 1), Vault Enterprise is deployed across 2 data centers, each containing a PR primary or secondary cluster and each paired with a DR cluster. Consider the case where cluster A fails: in this scenario the Vault operators will promote cluster B to become a DR and PR primary cluster.
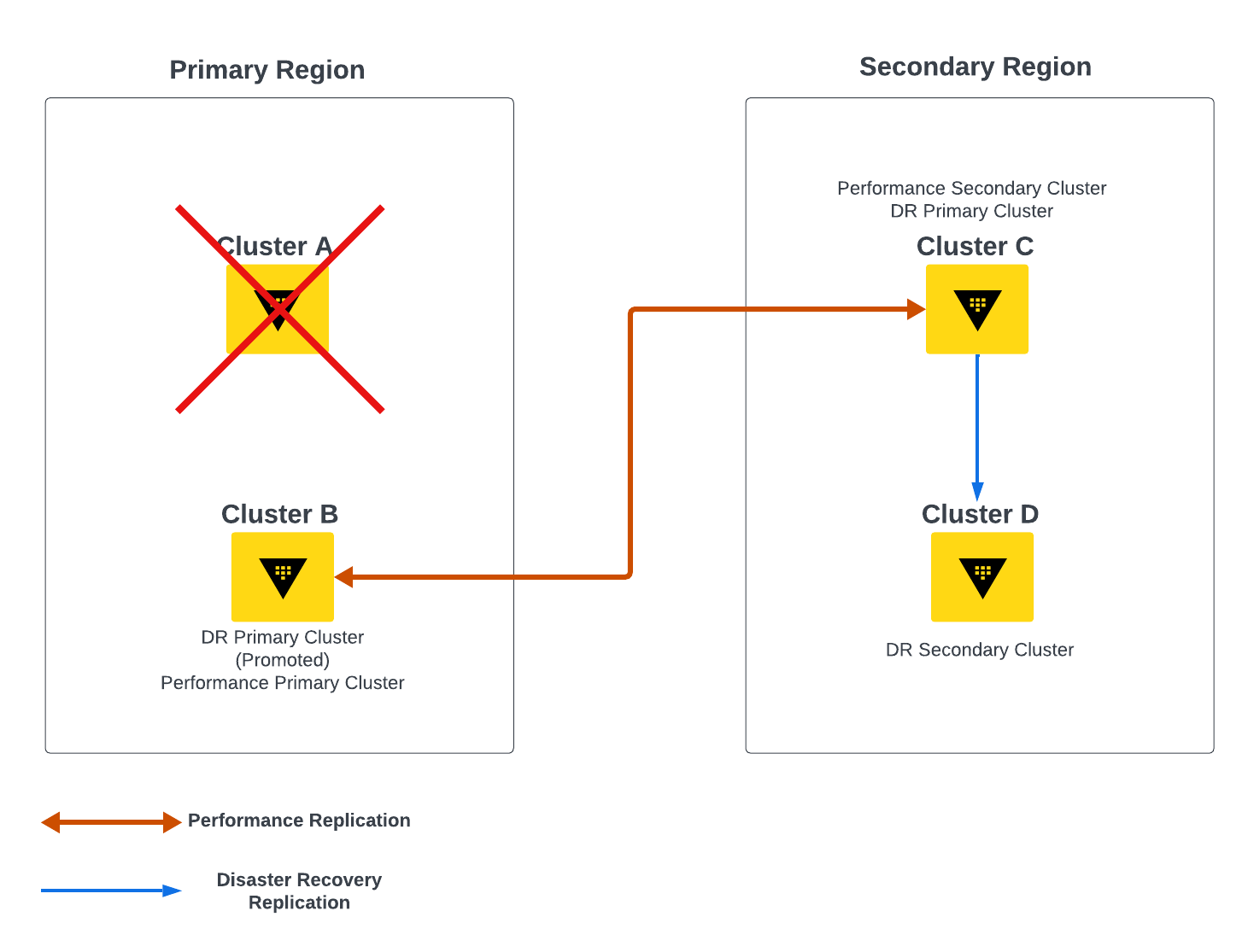 Figure 2. DR Scenario
Figure 2. DR Scenario
When cluster B is promoted to be a DR Primary, performance replication needs to be reestablished between cluster B and cluster C. Cluster C accomplishes this by keeping a list of DR secondary nodes associated with cluster A. These addresses are stored in an internal reference known as failover_addr on cluster C when replication is established. During normal operations, clusters A and C will communicate without issues. When cluster A fails, cluster C will attempt to establish communication for a few moments, and then will begin attempting to connect with the addresses stored in the failover_addr reference. Once cluster B is promoted to DR Primary, cluster C will be able to reestablish communication.
In most scenarios, performance replication should be able to reestablish automatically with a new DR primary cluster based on the procedure above. However, this requires that the PR secondary nodes have network access to the promoted DR primary nodes over the Vault cluster port (8201). It is important to ensure that this network connectivity requirement is considered during the design of your PR cluster. In scenarios where manual intervention may be necessary to update the cluster address used for replication on the PR secondary cluster, the /sys/replication/performance/secondary/update-primary API endpoint can be used to update the primary cluster address.
Setting up performance replication
Note
On HCP Vault dedicated, performance replica clusters are deployed through the HCP control plane. You will not need to configure the underlying infrastructure or go through the replication configuration if you are using HCP Vault Dedicated. Other considerations including those outlined above regarding interaction with Vault clients will still apply on HCP Vault Dedicated.Prerequisites
- You have deployed a separate Vault cluster that is intended for performance replication
- The PR replica Vault cluster is initialized and unsealed
- You have a valid token for your primary cluster and PR replica cluster
Networking considerations
Performance replication makes use of two TCP ports for communication between clusters: the Vault API port (TCP-8200) and the cluster port (TCP-8201). When replication is being established, a two step process takes place:
- First, the leader node in the PR secondary cluster sends an authentication request over TCP-8200 to the PR primary cluster using the encoded leader API address and batch token contained in the encoded replication token.
- Next, the secondary obtains a list of cluster addresses from the primary leader node, and initiates replication traffic on the cluster port over TCP-8201 with the primary leader node.
Note
If the network path between the two clusters does not allow direct network traffic on the cluster port (TCP-8201) between all of the nodes in each cluster, then you will need to manually set the primary cluster address to override the default encoded cluster address value for replication when you enable replication on the primary. This is often required when the primary cluster is only accessible via a network path that includes a load balancer.Additionally, note that replication traffic on the Vault cluster port (TCP-8201) must be directed to the leader node of the primary cluster. If a load balancer is the only network path for replication traffic on the cluster port (TCP-8201), the load balancer should be configured via health checks through the cluster port (TCP-8200) to determine the current leader node.
TLS Considerations
In step two above, while establishing a replication connection over the cluster port, mutual TLS authentication takes place between the PR secondary and primary cluster leaders, and replication traffic commences via HTTP/2 gRPC. Therefore, no intermediate TLS termination (such as using an intermediate load balancer serving a TLS certificate) can be in place on port TCP-8201 between the primary and secondary cluster. Otherwise the mutual TLS authentication process will fail and replication will not be enabled.
Set up process
Refer to this tutorial for the steps to set up performance replication. At a high level, the steps are:
- Enable performance replication on the primary cluster, obtaining a PR secondary activation token
- Using the PR secondary activation token, enable performance replication on the secondary cluster
- Verify and monitor performance replication
Note
Vault does not replicate automated integrated storage snapshots as a part of performance replication. You must explicitly configure both the primary and secondary performance clusters to create individual automated snapshots. However, this is not the case for audit devices. Vault replicates the configuration of audit devices as part of performance replication. This means that the same directory (for file-based devices) or the same endpoint (for socket-based devices) must be reachable by all the nodes in the PR cluster.Monitoring performance replication
The health of Vault performance replication should be monitored. Monitoring Vault performance replication should include ensuring that:
- Both the primary and secondary clusters are online and in a healthy state
- Network communication between the primary and secondary clusters has not become disrupted
- Replication subsystem in Vault is operating in a healthy state on primary and secondary clusters and that data sync is keeping pace between the two
For item number one, refer to the Vault: Operating Guide for Adoption to ensure that telemetry has been configured on primary and secondary clusters, and the outlined key metrics are being monitored for general cluster health.
For item number two, a synthetic check can be run periodically against the sys/replication/performance/status API endpoint on both clusters to check the value of the “state” field. If the value of the state field is “idle” then this indicates that communication may have become disrupted and replication is no longer taking place. The progress and health of synchronization between primary and secondary clusters can be checked by querying the sys/replication/performance/status API endpoint on both clusters and comparing the values of last_performance_wal on the primary and last_remote_wal on the secondary. After writing a piece of replicated data, the last_remote_wal on the secondary should match the last_performance_wal on the primary for a short period of time.
For item number three, there are specific Vault telemetry values that should be monitored to indicate the health of the replication subsystem:
| Metric Name | Description |
|---|---|
| vault.wal_persistwals | Time taken to persist a WAL to storage |
| vault.wal_flushready | Time taken to flush a ready WAL to storage |
These metrics indicate the time being taken in the replication subsystem to process write ahead logs (WALs). Both of these metrics should be monitored for a situation where the values continue to grow without returning to the expected baseline. In a high-load scenario, WALs can accumulate, putting pressure on Vault’s storage backend.